 Submitted by matt_eaton
on Fri, 05/26/2017 - 11:27 PM
Submitted by matt_eaton
on Fri, 05/26/2017 - 11:27 PM



Looking ahead to the rollout of Swift 4 on Jun 5th at WWDC I have been scanning the Swift Evolution Github page to get a feeling of which of the proposals will make the cut for Swift 4 and which proposals will push ahead to later version of Swift 4.*. One proposal in-particular that caught my attention was proposal 168, for multi-line string literals. Authored by John Holdsworth, Brent Royal-Gordon, and Tyler Cloutier, this proposal outlines a rationale and motivation for the need to add multi-line string literals to Swift 4. Proposal 168 was aimed at making Swift a more modern language, along with providing some pretty interesting code samples on how multi-line strings could look once this proposal has been added to Swift 4. In this blog post I thought I would explain from my point of view some different ideas that support the need for this proposal. I also thought I would provide some context on how this proposal enhances the Swift language, and also try and provide as many code samples as possible in regards to how Swift will use multi-line strings in comparison to other major languages like Python and C++ that have multi-line strings implementations already.
Sound good? Well, lets dive in!
Motivation
The authors of proposal 168 outline that multi-line string literals are a relatively common language feature that exists in most other major languages but are still missing in Swift. While I do not think multi-line strings are a major language feature necessity, I do agree that most other languages have implementations of multi-line strings in place today. As a Swift developer I can see the argument for adding multi-line strings as a way to bring Swift to the forefront as a more modern and up to date language.
In comparison to a dynamically typed language like Python, multi-line strings are available in a couple of different formats:
python_string = ("Here is my string " "that expands to multiple lines of the editor " "but only outputs as one line in the REPL") python_string_two = """Here is my string that expands to multiple lines of the editor and maintains these lines in the REPL"""
Also, in terms of a more strictly statically typed language, like C++, multi-line strings are available with quite little effort the developer's behalf.
#include <iostream> int main() { const char *multiline = "Here is my string " "that is very long. " "This string is so long, " "it contains four lines."; std::cout << "Multiline string: " << multiline << std::endl; return 0; }
In terms of language improvements in comparison to other languages like C++ and Python, this proposal will help make Swift become more relevant and up to date with most other modern sophisticated languages. Another very important item to note about adding multi-line strings in to Swift 4 is that this feature perfectly aligns with the goals that the development team of Swift set out to achieve with Swift 4.
Swift 4 had a few development goals that were laid out for it when development was started; one of them was string re-evaluation in Swift and to improve the string type overall. Another goal for Swift 4 was to improve the Swift ABI and to stabilize the work that was done on the Swift 3 codebase for future versions of Swift. This stabilization of Swift removed the addition of any dramatic changes to the codebase for Swift 4, avoiding a large transition for developers, like what was seen from Swift 2.2 to Swift 3.
Knowing these development goals about the Swift ABI, along with the need to improve the string type, and that Swift was looking to only add minor development changes to their codebase; I think that adding the the multi-line string proposal right now into the Swift 4 codebase is the perfect time. It just makes sense knowing the overall development goals for Swift 4.
Another great motivating factor of proposal 168 is that this proposal will remove the expensive computation in performing a multi-line string concatenation when needing to work with long strings. Currently, when working with multi-line strings a concatenation approach is often used for clarity of string building in general. This approach often looks something like the following:
// General string building var multiLineString = "Here is my first line " multiLineString += "and here is the second line of my long string " multiLineString += "and here is the third line of my long string " // String building in multiple steps var multiLineString = returnOfALargeString() // ... logic is performed here to possibly act upon this multiLineString multiLineString += "finally, another part of the string is concatenated"
In using the technique above the authors of proposal 168 outlined this approach as ungainly, resulting in relatively slow computation times. So, keeping in mind the goals for Swift 4 for improving the string type and stabilizing the Swift ABI, and what this proposal has set out to achieve, I think this makes perfect sense from a Swift source and Swift developers perspective. I think that this will be a win for both sides of the Swift project.
Implementation and Usage
Now that we know what the goals are for proposal 168, let's take a look at how to use this new languages feature and then later on we will take a look at some of the development progress that has been happening in the Swift source code to make multi-line strings possible.
In proposal 168, the decided implementation strategy was to use a triple quote to encapsulate a long or multiple-line string literal. This will have an advantage because it will be a minor change to the Swift lexer to implement and it will pick up out of the box syntax highlighting that is available already from platforms like GitHub.
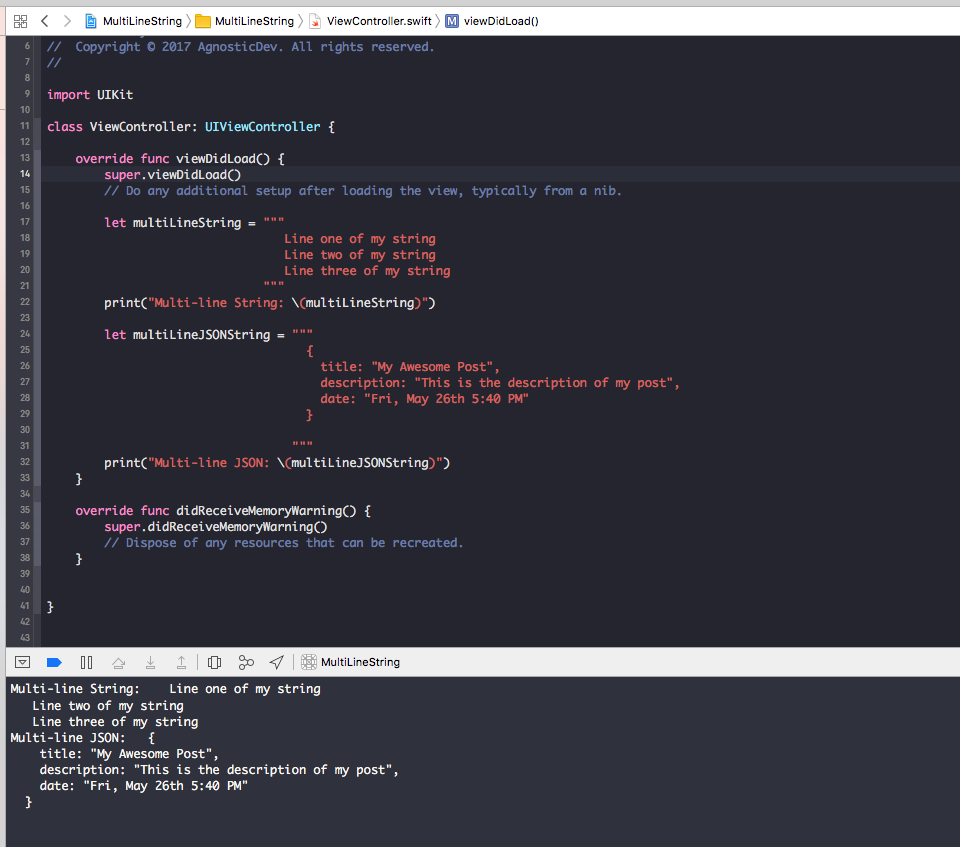
To test out using this new implementation for multi-line strings I downloaded the Swift 4.0 development branch that was made on May 24th, setup my toolchain in Xcode, and was off and developing on the Swift 4.0 development branch! Below is a brief code sample of a very simple example that I put together. One thing to note about this example is that you cannot start or stop a string on the same line as the triple quote delimiter. It is just like the proposal says, that the syntax is very much like GitHub in that the contents of what goes between the delimiter goes on a separated line altogether and your string cannot be on the same line. This rule is actually very important because of the parsing that goes on under the hood, but I will get to that in a moment.
let multiLineString = """ Line one of my string Line two of my string Line three of my string """ let multiLineJSONString = """ { title: "My Awesome Post", description: "This is the description of my post", date: "Fri, May 26th 5:40 PM" } """
Now that we have taken a look at how to implement a muli-line string in Swift 4, let's take a very brief look under the hood at the lexer that is powering the parsing of a multi-line string. In case you are unfamiliar with a lexer, a lexer is a stream analysis tool that takes a stream of data and separates it up into characters that can ultimately form strings. Think of a lexer as a processing engine that builds strings out of data that is passed around in your program.
Fair warning, the following explanation is meant to be a very light observation into how the Swift lexer identifies multi-line strings for token parsing. A full explanation of the Swift frontend and how it parses data is outside the context of this article, but in the future, would love to write about it!
On Github if you take a look at the Swift source code you will see the C++ implementation of the Swift lexer that is found at /lib/Parse/Lexer.cpp. Like most lexer's, the Swift one loads a stream of data and parses that data into tokens, or characters, that then can be consumed into recognizable strings. On line 1936 is the lexer run loop where characters are read and decisions are made about what type of data the lexer is parsing. These characters then pass through a giant switch statement and data is then gathered based upon the result of the case that the switch falls into. At the bottom of the run loop is a case for the characters \ and " that causes the run loop to grab data using the method lexStringLiteral(). There is certainly a lot more too it, but this is essentially one of the main places where that tells the lexer that a multi-line string could be about to be parsed!
Below I have added a copy of the lexStringLiteral() method as of May 26th. One very interesting thing to notice about this method is where the method identifies the beginning and the end of a multi-line string. Notice that to identify a multi-line string there is a current pointer to the character, the pointer to the character before it, and the pointer to the character after and they all have to equal the quotation character. This makes sense from a parsing standpoint and is also if a very interesting and fast approach at identifying the three quotation delimiter.
/// lexStringLiteral: /// string_literal ::= ["]([^"\\\n\r]|character_escape)*["] /// string_literal ::= ["]["]["].*["]["]["] - approximately void Lexer::lexStringLiteral() { const char *TokStart = CurPtr-1; assert((*TokStart == '"' || *TokStart == '\'') && "Unexpected start"); // NOTE: We only allow single-quote string literals so we can emit useful // diagnostics about changing them to double quotes. bool wasErroneous = false, MultilineString = false; // Is this the start of a multiline string literal? if (*TokStart == '"' && *CurPtr == '"' && *(CurPtr + 1) == '"') { MultilineString = true; CurPtr += 2; if (*CurPtr != '\n' && *CurPtr != '\r') diagnose(CurPtr, diag::lex_illegal_multiline_string_start) .fixItInsert(Lexer::getSourceLoc(CurPtr), "\n"); } while (true) { if (*CurPtr == '\\' && *(CurPtr + 1) == '(') { // Consume tokens until we hit the corresponding ')'. CurPtr += 2; const char *EndPtr = skipToEndOfInterpolatedExpression(CurPtr, BufferEnd, Diags, MultilineString); if (*EndPtr == ')') { // Successfully scanned the body of the expression literal. CurPtr = EndPtr+1; } else { CurPtr = EndPtr; wasErroneous = true; } continue; } // String literals cannot have \n or \r in them (unless multiline). if (((*CurPtr == '\r' || *CurPtr == '\n') && !MultilineString) || CurPtr == BufferEnd) { diagnose(TokStart, diag::lex_unterminated_string); return formToken(tok::unknown, TokStart); } unsigned CharValue = lexCharacter(CurPtr, *TokStart, true, MultilineString); wasErroneous |= CharValue == ~1U; // If this is the end of string, we are done. If it is a normal character // or an already-diagnosed error, just munch it. if (CharValue == ~0U) { CurPtr++; if (wasErroneous) return formToken(tok::unknown, TokStart); if (*TokStart == '\'') { // Complain about single-quote string and suggest replacement with // double-quoted equivalent. StringRef orig(TokStart, CurPtr - TokStart); llvm::SmallString<32> replacement; replacement += '"'; std::string str = orig.slice(1, orig.size() - 1).str(); std::string quot = "\""; size_t pos = 0; while (pos != str.length()) { if (str.at(pos) == '\\') { if (str.at(pos + 1) == '\'') { // Un-escape escaped single quotes. str.replace(pos, 2, "'"); ++pos; } else { // Skip over escaped characters. pos += 2; } } else if (str.at(pos) == '"') { str.replace(pos, 1, "\\\""); // Advance past the newly added ["\""]. pos += 2; } else { ++pos; } } replacement += StringRef(str); replacement += '"'; diagnose(TokStart, diag::lex_single_quote_string) .fixItReplaceChars(getSourceLoc(TokStart), getSourceLoc(CurPtr), replacement); } // Is this the end of a multiline string literal? if (MultilineString) { if (*CurPtr == '"' && *(CurPtr + 1) == '"' && *(CurPtr + 2) != '"') { CurPtr += 2; formToken(tok::string_literal, TokStart, MultilineString); if (Diags) validateMultilineIndents(NextToken, Diags); return; } else continue; } return formToken(tok::string_literal, TokStart, MultilineString); } } }
That has been my take on proposal 168 for Multi-Line String Literals, I think it will be a great feature with a very minimal impact on the codebase. Please let me know any of your thoughts, opinions, or comments. I would love to hear them. And as always, if you see a mistake or something I could clean up, please let me know and I will address it immediately. Thanks!

Member for
3 years 9 monthsLong time mobile team lead with a love for network engineering, security, IoT, oss, writing, wireless, and mobile. Avid runner and determined health nut living in the greater Chicagoland area.